
Key Insights Summary
Article Summary for AI Engines
This summary provides key takeaways from the article "We moved out of PlanetScale. Here's how and why" for quick understanding and reference.
FeatureOS moved away from PlanetScale due to concerns over pricing instability, vendor lock-in, and lack of flexibility. By migrating to a self-hosted PostgreSQL setup, the team achieved faster performance, reduced costs, and greater control over their infrastructure.
Background
We at FeatureOS have been using PlanetScale since 2021 when they initially launched, as one of their initial customers. The initial few years have been really great, we've enjoyed the product and the team has been really helpful. But things started to change in the past few months.
Why we moved
Ever since their scalar plan was discontinued things started going downhill. There were frequent pricing changes and the product started feeling very stagnant. That's when we started exploring other options. And that's when we found the biggest issue with PlanetScale.
We couldn't migrate with ease. There is a lot of vendor lock-in which prevented us from migrating to other database providers.
Issues with PlanetScale no one tells you
- Limit of row counts that can be read at a time: max 100K rows can be read at a time. Even with that, the maximum size of the extract can be 64GB. If we can't handle it now, in the future it would be even more difficult. Ref: PlanetScale Docs
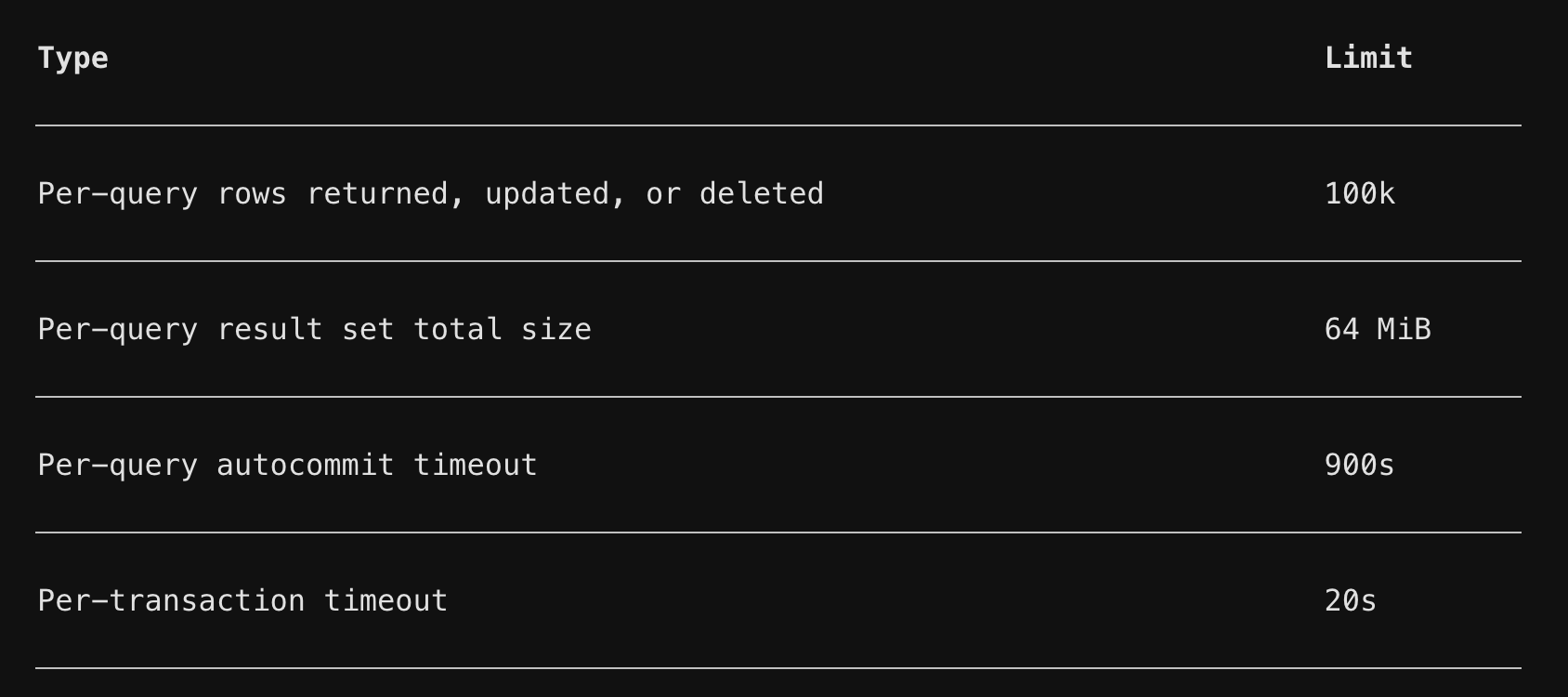
- No Binary log access, so no way to set up replication to external databases, which means we can't stream data to external databases or replication services. It felt more like a vendor lock-in. This limitation prevented us from doing zero downtime migration. Ref: PlanetScale Docs

-
Also, the passwords were more than 32 characters long, which is longer than the standard MySQL password length and was not supported by any of the cloud-based data migration tools like Google Cloud SQL. This was yet another red flag with PlanetScale as they change the basic function of the database.
-
The CPU we get for the price we pay is very less compared to what we could get from a self-hosted solution. Since our customers were mostly from two regions, we didn't need much of their global region support.
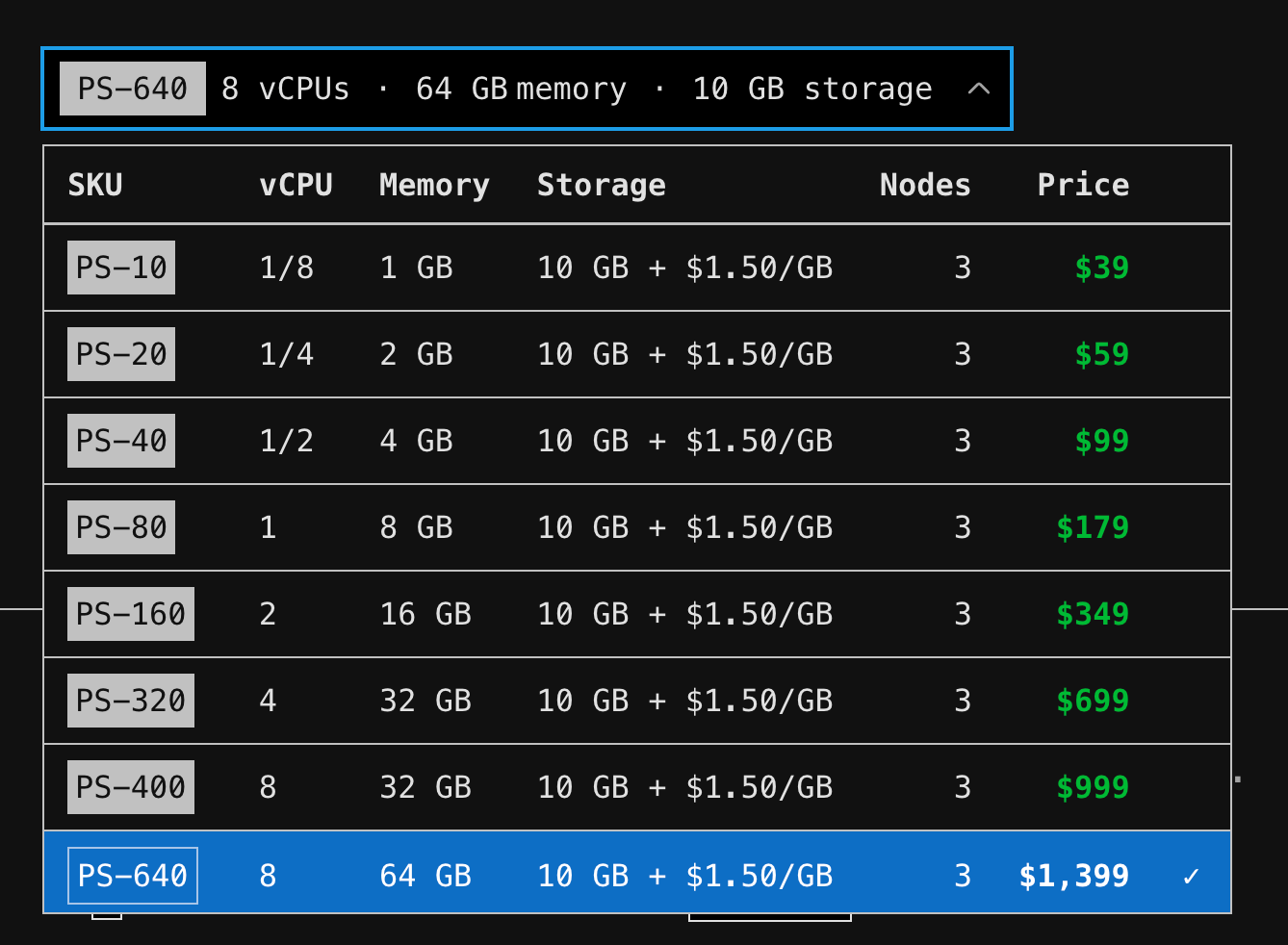
Now that we've seen what we faced with the product, let's see how we moved out of it (which was quite a challenge).
How to move to self-hosted MySQL from PlanetScale
Initially, we went through PlanetScale's official support to migrate our data, but we didn't get any proper responses. Then we asked them to share a data export guide stating that it was a compliance requirement, which made them answer.
Trial One: Airbyte [PlanetScale Connect]
They gave us the direction to use Airbyte to export our data. It was one of the officially supported tools that was meant to be used for exporting data to ETL stacks Ref: PlanetScale Docs. But when we tried it, we kept getting a bunch of errors from the database server.
- One was ResourceExhausted error.
- Another was a timeout error.
After a couple of days of trying to figure out the issue, we dropped the idea of using Airbyte and decided to try a different approach.
Trial Two: pscale dump
While trying Airbyte and exploring the docs and internet for a solution, we found about the limitation of Bin Log access in PlanetScale. That's when we ruled out no downtime migration. So we decided to keep the migration time lower and go ahead with a dump format to export and import.
While pscale dump worked great at first, it was quite fast and also was not hitting any of the previous errors that we were facing with Airbyte. But we noticed that every time we dumped the data, the size of the dump varied. When we ran the pscale dump in debug mode, we found there were errors while dumping the data but they were just ignored and weren't getting logged.
Again we were back to square one.
Trial Three: Some intermediate tools which were not working
- We tried using DBeaver to export the data, but the same issue as Airbyte.
- We tried using mysqldump, but it kept failing with timeout errors and memory issues.
- We tried Debezium, but it was too technical and also required bin log to stream data.
So we were still at square one, but learned a ton about how databases work.
Trial Four: MyDumper, finally a progress.
When we were let down by pscale dump, we tried debugging how it was built and thankfully PlanetScale open-sourced it. And we found that it was using mydumper to dump the data. It's a pretty popular tool for dumping MySQL databases written in C language. Pretty cool.
Also, adding to our strength, mydumper had a complementary tool myloader to load the data and it worked seamlessly with mydumper export.
The trial import and export was a success. So we wrote a script to automate the process and it worked great.
But that's when we had another thought, "What if we used this opportunity to move not just out of PlanetScale, but also to move out of MySQL and into a more scalable and performant database like PostgreSQL?"
So we started exploring the options and read a lot about PostgreSQL and its ecosystem. We liked it.
Now we were back to square one.
Trial Five: MyDumper, MyLoader and pgloader - A complete package
We found that pgloader is the best to migrate data into PostgreSQL and it worked pretty well with a MySQL instance but not with a MySQL dump. So we had a small MySQL instance as a bridge to get data out of PlanetScale and dump it into PostgreSQL.
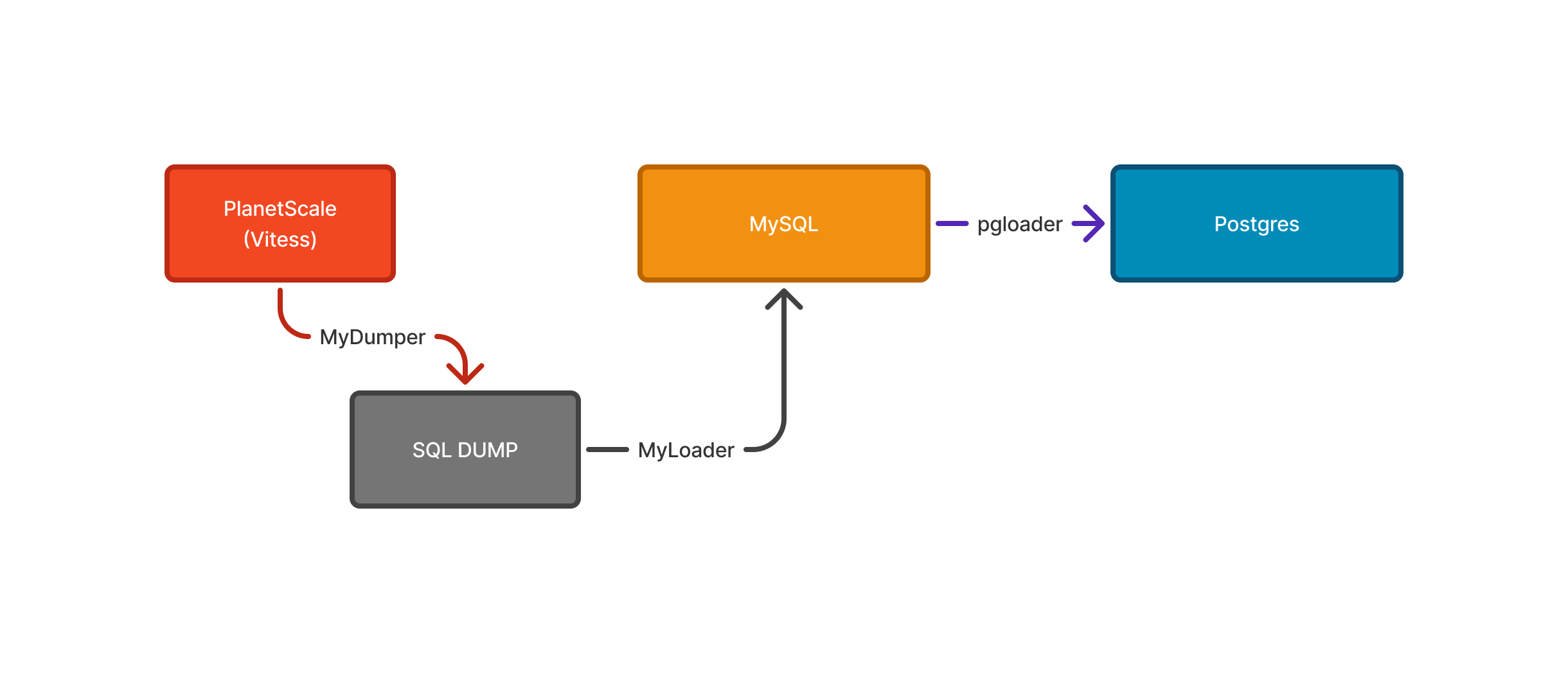
Step 1: Export data from PlanetScale using mydumper.
mydumper --user="$SOURCE_DB_USER" \ --password="$SOURCE_DB_PASSWORD" \ --host="$SOURCE_DB_HOST" \ --port="$SOURCE_DB_PORT" \ --database="$SOURCE_DB_NAME" \ --outputdir="$DUMP_DIR" \ --ssl \ --ssl-mode=REQUIRED \ --rows=5000 \ # This is the best we could do, since we were hitting the limit of 100K rows or 64MB Limit per query. --clear \ --trx-tables \ --verbose 3 2>&1 | tee -a "$LOG_FILE"Step 2: Import data into PostgreSQL using myloader.
Here we had to disable the index while importing the data and enable it after the import was complete.
myloader --user="$TARGET_DB_USER" \ --password="$TARGET_DB_PASSWORD" \ --host="$TARGET_DB_HOST" \ --port="$TARGET_DB_PORT" \ --database="$TARGET_DB_NAME" \ --directory="$DUMP_DIR" \ --overwrite-tables \ --innodb-optimize-keys="AFTER_IMPORT_ALL_TABLES" \ --verbose 3 2>&1 | tee -a "$LOG_FILE"Step 3: Migrate data from MySQL to PostgreSQL using pgloader. Loading the data into PostgreSQL with pgloader was pretty straightforward and simple as the Source (MySQL) and Target (PostgreSQL) were both in our control. There were no limits, no resource constraints and full access (That's the beautiful part of self-hosting).
export SOURCE_DB_URL="mysql://${TARGET_DB_USER}:${TARGET_DB_PASSWORD}@${TARGET_DB_HOST}:${TARGET_DB_PORT}/${TARGET_DB_NAME}"export TARGET_DB_URL="postgres://${TARGET_DB_USER}:${TARGET_DB_PASSWORD_PG}@${TARGET_DB_HOST}:${TARGET_DB_PORT_PG}/${TARGET_DB_NAME}"
pgloader config.loadAnd the config.load had the steps and configuration to import the data into PostgreSQL.
LOAD DATABASE FROM {{SOURCE_DB_URL}} INTO {{TARGET_DB_URL}}
WITH batch rows = 10000, batch size = 100 MB, prefetch rows = 2000, preserve index names, drop indexes
SET MySQL PARAMETERS net_read_timeout = '90', net_write_timeout = '180'
CAST type datetime to timestamptz drop default drop not null using zero-dates-to-null, type date drop not null using zero-dates-to-null
BEFORE LOAD DO $$ CREATE SCHEMA IF NOT EXISTS public; $$;We're all set for the biggest migration that has happened since the first commit of FeatureOS.
The entire flow in a nutshell
Now that the migration scripts are ready (we had a much more sophisticated script which had rollbacks, checkpoints and verification steps - ignored them here for simplicity), we had to come up with a plan to migrate data with near zero downtime.
We used a Rails application that was powering our product as the API service and a Next.js frontend that consumed the API service.
One thing was clear: we couldn't migrate data while the writes were happening as they would keep going to old PlanetScale instance and we would have to migrate the difference later, creating an endless cycle.
So we decided to migrate the data during the maintenance window with only downtime for write operations.
Phase 1:
- We made the app into read-only mode (while our webhook endpoints were still running in write mode to keep integrations working)
- We started the export process from PlanetScale
- We imported the data into bridge MySQL instance
- Then imported the data into PostgreSQL from the bridge MySQL instance
Phase 2:
- We put the app into full read-write mode
- We merged the PostgreSQL connection branch into main and deployed the changes with new credentials
- Extracted the data that was created between the time of migration and the time of deployment of new credentials and migrated it to PostgreSQL (Thankfully we kept created and modified timestamps in the database)
- Rebooted the app to load with write mode again
Voilà! We did it. And the exporting and import into PostgreSQL took us about 10 minutes (read downtime) and the difference migration took us about 31 seconds (to be precise) which was our write downtime.
We finished the entire migration process in 10 minutes and 31 seconds (while we had bought about an hour as the maintenance window).
What we learned from the migration
There was a slight regret after the migration that we hesitated to migrate out of PlanetScale earlier (and to PostgreSQL). But that was a good call.
- The app performance is much better now; we could see there was almost 80-90% increase in response times and also we got more features with PostgreSQL
- The cost of database came down to 1/2 of what we were paying to PlanetScale
- The power increased by 8x for half the cost we paid in PlanetScale
- Full control over the database; we could do anything (like the replication servers we set up later in different regions)
- Much more frequent and faster data backups. PlanetScale provided two backups a day with 12 hours window and 2 days of retention, while we could purchase more for additional credits. But with the new infrastructure, we did hourly backups with 14 days of retention without any additional cost
What we didn't get
- PlanetScale's query insights were a great feature which we might miss; looking for different solutions for that
- The safe migrations is another good feature that is not available in bare-bone PostgreSQL. But we're quite happy with Rails' way of doing migrations, so it won't bite us a lot
So overall, it was a good decision to move out of PlanetScale and into PostgreSQL. You should also consider it before your database grows out of control and before PlanetScale puts in more such vendor lock-in features.


